
wholeTextFiles() PySpark: wholeTextFiles() function in PySpark to read all text files
In this section we will show you the examples of wholeTextFiles() function in PySpark, which is used to read the text data in PySpark program. This function is powerful function to read multiple text files from a directory in a go. This program will read just read all the files in a directory, but can't read the files present in sub-directories. If you have multiple files in sub-directories this program won't work and you have to write your own logic to read files in sub-directories. This function runs pretty well if you have to read text files present in a directory. So, let's see how the use the wholeTextFiles() function in PySpark?
In Big Data applications developers may have to read large number of text file to process it on the spark cluster. In this case the wholeTextFiles() function is very useful as it comes with the feature of reading any number of files in paired RDD.
Once the text files are loaded into RDD developers may apply other data processing logic as per their project specifications. Many industries are processing large number of text files and saving final results to the Big Data into hive or in csv format. In this section we discussing about reading the text files in Apache Spark RDD and then show you how to collect the data, which is then printed on the console.

What is wholeTextFiles() function in PySpark?
The wholeTextFiles() function comes with Spark Context (sc) object in PySpark and it takes file path (directory path from where files is to be read) for reading all the files in the directory. Here is the signature of the function:
wholeTextFiles(path, minPartitions=None, use_unicode=True)
This function takes path, minPartitions and the use_unicode parameters to read the text files present in the directory. You will be able to provide the minPartitions and use_unicode parameters to this function, these two parameters are optional.
This function can be used to read a HDFS directory, a local file system directory from the Spark Program. The wholeTextFiles() function reads files data into paired rdd where first column is the file path and second column contains the file data. For example if you have 10 text files in your directory then there will be 10 rows in your rdd. The default value of use_unicode is False, which means the file data (strings) will be kept as str (encoding as utf-8).
The wholeTextFiles() function of SparkContext is very handy and provides very easy way to read text files into paired RDD in Spark. This function is available for Java, Scala and Python in Apache Spark. The final output of this function is paired RDD where file path is the key and the file content is the value in the RDD. After reading the files into RDD developers can use this RDD for further processing of the file data.
How wholeTextFiles() function in PySpark works?
Here is the functioning of wholeTextFiles() function in Apache Spark:
- First of program reads and lists all the relevant files
present in the given directory or paths. The wholeTextFiles()
function runs this steps in parallel if the underlying file
system supports. This is taken as input for the next step.
- Then the program groups the original input into bigger
chunks which is later split for fast processing. In the Spark
API if can control the number of partitions while calling the
wholeTextFiles()by specifying the minPartitions value.
- When any transformation and actions are performed on the RDD the data is loaded into the memory for processing.
Example of wholeTextFiles() function in PySpark
Here is example of wholeTextFiles() function in PySpark which reads the data into RDD and then prints on the console:
fileRDD = sc.wholeTextFiles("/home/deepak/data/")
rdd = fileRDD.collect()
# print Data
for row in rdd:
print(row)
Above program reads the text files using the wholeTextFiles() function in Apache Spark and prints the content of file.
Here is the screen shot of the program execution:
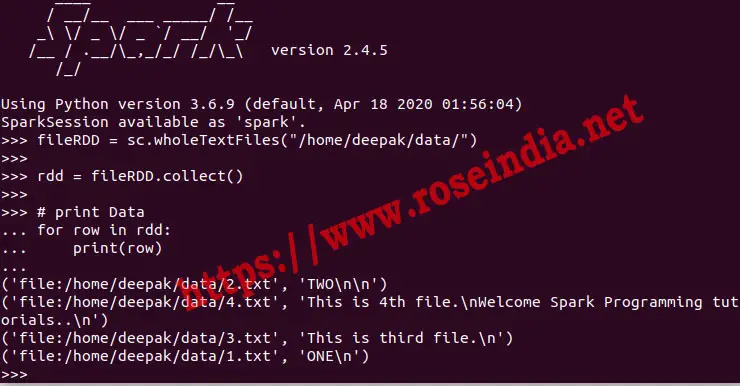
Here is the output of the program:
>>> fileRDD = sc.wholeTextFiles("/home/deepak/data/")
>>>
>>> rdd = fileRDD.collect()
>>>
>>> # print Data
... for row in rdd:
... print(row)
...
('file:/home/deepak/data/2.txt', 'TWO\n\n')
('file:/home/deepak/data/4.txt', 'This is 4th file.\nWelcome Spark Programming tutorials..\n')
('file:/home/deepak/data/3.txt', 'This is third file.\n')
('file:/home/deepak/data/1.txt', 'ONE\n')
>>>
We have large number of Spark tutorials and you can view all these tutorials at: