
PySpark Hello World - Learn to write and run first PySpark code
In this section we will write a program in PySpark that counts the number of characters in the "Hello World" text. We will learn how to run it from pyspark shell.
In the previous session we have installed Spark and explained how to open the pyspark shell.
The pyspark shell of Spark allows the developers to interactively type python command and run it on the Spark.
Let's get started.
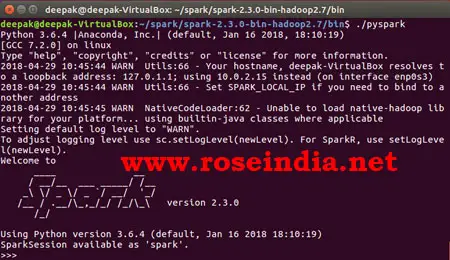
Open terminal in Ubuntu by typing ./pyspark inside the bin directory of Spark installation.
It will show the following window and provide a prompt where you can write your code. Our first program is simple pyspark program for calculating number of characters in the word.
./pyspark
Here is pyspark shell:
We will run following code on the shell:
from pyspark import SparkContext
from operator import add
data = sc.parallelize(list("Hello World"))
counts = data.map(lambda x:
(x, 1)).reduceByKey(add).sortBy(lambda x: x[1],
ascending=False).collect()
for (word, count) in counts:
print("{}: {}".format(word, count))
In the first two lines we are importing the Spark and Python libraries.
from pyspark import SparkContext
from operator import add
Next we will create RDD from "Hello World" string:
data = sc.parallelize(list("Hello World"))
Here we have used the object sc, sc is the SparkContext object which is created by pyspark before showing the console.
The parallelize() function is used to create RDD from String. RDD is also know as Resilient Distributed Datasets which is distributed data set in Spark. RDD process is done on the distributed Spark cluster.
Now with the following example we calculate number of characters and print on the console.
counts = data.map(lambda x:
(x, 1)).reduceByKey(add).sortBy(lambda x: x[1],
ascending=False).collect()
for (word, count) in counts:
print("{}: {}".format(word, count))
Above program prints following data:
deepak@deepak-VirtualBox:~/spark/spark-2.3.0-bin-hadoop2.7/bin$ ./pyspark
Python 3.6.4 |Anaconda, Inc.| (default, Jan 16 2018, 18:10:19)
[GCC 7.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
2018-04-29 14:44:37 WARN Utils:66 - Your hostname, deepak-VirtualBox resolves to a loopback address: 127.0.1.1; using 10.0.2.15 instead (on interface enp0s3)
2018-04-29 14:44:37 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address
2018-04-29 14:44:37 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.3.0
/_/
Using Python version 3.6.4 (default, Jan 16 2018 18:10:19)
SparkSession available as 'spark'.
>>> from pyspark import SparkContext
>>> from operator import add
>>>
...
>>> data = sc.parallelize(list("Hello World"))
>>> counts = data.map(lambda x:
... (x, 1)).reduceByKey(add).sortBy(lambda x: x[1],
... ascending=False).collect()
>>>
>>> for (word, count) in counts:
... print("{}: {}".format(word, count))
...
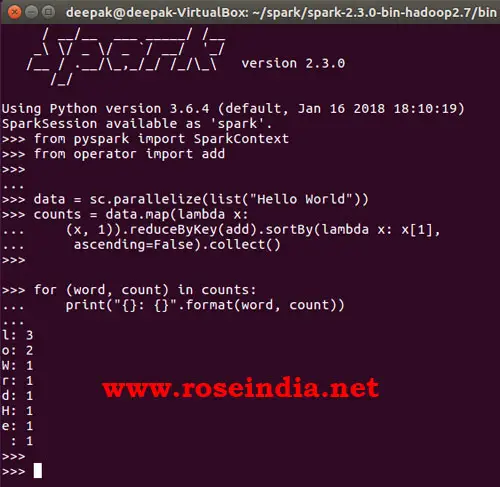
l: 3
o: 2
W: 1
r: 1
d: 1
H: 1
e: 1
: 1
>>>
>>>
If you you run the program you will get following results:
Now can quit terminal by typing:
>>> exit()
In this tutorial your leaned how to many your first Hello World pyspark program.