
Mastering RDD in Apache Spark - Resilient Distributed Dataset (RDD) Features, Advantages, and Applications explained
In this tutorial we are going to explore the Resilient Distributed Dataset (RDD) in much in-depth and explain to you the core concepts with help of many examples. You will be able to learn and master RDD by practicing the examples provided in this tutorial. We have used PySpark (Python) for developing programs for these tutorials. If you don’t know Python learn it at our Python Tutorials section.
In this tutorial you will learn Apache Spark RDD and learning RDD help you in unleashing the full potential of Spark for your project. RDD is part of core API’s of Apache spark and learning this API is the first step in the world of Spark based data engineering project. RDDs can be used for large scale raw data processing in the big-data world.

In this post we are going to understand RDD’s core features, advantages and various use cases for processing data on the distributed spark clutter. Understanding of RDD will help you designing and developing large scale data process pipelines. Let’s get started with Apache Spark RDDs.
What are prerequisites for learning RDD in Apache Spark?
You should have a basic understanding of Apache Spark and experience in any of the programming languages. You should have working knowledge of Python and databases.
- Prior experience in any of the programming language
- Basic Knowledge of Apache Spark
- Experience or working knowledge of Python
- Understanding of databases and SQL
- Pre-installed Apache Spark on your favouried operating system for running code examples described here.
Introduction to RDD
The Apache Spark Resilient Distributed Dataset is also known as RDD, which is a fundamental data structure for working with data in Spark. RDD is used to store data in-memory on the spark cluster for distributed data processing in a fault-tolerant way. The RDD is an immutable distributed data structure, which is divided into logical partitions and data is processed on the different nodes in the cluster. In Apache Spark data (RDD) is loaded in the memory of worker nodes where actual data processing is performed.
You can use Java, Python or Scala for programming in Spark. So, RDDs can be objects in the Java, Python, Scala objects and in the user-defined classes. Data processing operations are executed on the distributed cluster in parallel and in fault-tolerant manager.
The object of RDD can be created by parallelizing an existing collection on the driver node or by loading the data from external storage for example loading .txt file data into RDD. In this tutorial we will show you many different ways of creating the RDD and then processing the data over a distributed Apache Spark cluster.
What is an RDD and what are its key concepts?
In the above introduction section we introduced you with the RDD, now lets see it in more detail. Resilient Distributed Dataset is also known as RDD in short and it's a distributed collection of objects, which can be processed in parallel on the distributed Apache Spark Cluster. RDD’s are immutable collections of data which can’t be modified, new RDD is created by performing transformations on the RDDs.
Key Concepts of RDDs are:
- Distributed: RDD’s Data are partitioned and distributed across multiple nodes for parallel processing.
- Resilient: RDD’s are resilient databases and the fault tolerance is achieved by managing the lineage information.
- Data Support: RDD supports structured, semi-structured, or unstructured data processing. RDD’s are also used in the AI/ML model training on Apache Spark Cluster.
How RDD Works?
RDD is a data structure for Apache Spark and its working means the creation, use, and finally disposing of the data structure objects. So, let's see how RDD is created, used and finally removed from the memory.
Here are the details on working of RDDs:
- RDD Creation: RDD’s are created by Loading Data from external storage like HDFS, S3, or a local file system. RDD’s can also be created by existing Python list, map, dictionary.
- New RDD creation through Transformations: Applying operations like map, filter, or reduceByKey creates a new RDD. It is not to be noted that RDD’s are immutable and new RDD’s are created with map, filter, or reduceByKey operations.
- Actions: RDD actions are specific actions on the Resilient Distributed Datasets (RDDs) that return the value on the driver node. Examples of such operations are e.g., collect or count. In the below sections we will discuss all the actions with example code.
Core Features of RDD
Let's discuss the core features of RDD.
1. In-Memory Data Processing
Apache Spark is an in-memory distributed data processing engine. RDDs are created and stored in the memory of worker nodes. The in-memory computation is fast as there is no overhead of loading the data from disk. RDDs are much faster than the disk based systems.
2. Fault Tolerant
Apache Spark uses the data lineage graph to enable fault tolerance. RDDs are fault tolerant due to the lineage graph feature of spark. If some data is lost due to crashing of the worker node even though the lost data is re-computed on the other worker node. For example if a partition is lost due to crash then Spark rebuilds it by reapplying transformations on the other worker node.
3. RDD is immutable
RDDs are immutable and once created it can’t be modified. New RDD’s are created by performing transformations on the existing RDDs. The immutability of RDD simplifies data handling in Apache Spark. It ensures the data integrity and helps in debugging the program in a better manner. If some part of RDD is lost due to node crash, the lost part can be generated by applying the transformation on the previous RDD. So, immutability of RDD is very important in Apache Spark.
4. Lazy Evaluation
Lazy Evaluation of RDDs are another top feature of Apache Spark as it is one of the factors of high performance in Apache Spark. Any of the transformation operations on RDDs are not executed immediately in Apache Spark, instead it is triggered when certain actions are invoked. Lazy Evaluation of RDDs results into well optimised execution plan and minimal use of resources on the cluster.
5. Partitioning
Apache Spark is a distributed in-memory computing engine and it partitions RDD data into multiple partitions. Partitioned RDDs are sent to the different worker nodes. When actions and transformations are invoked data processing is done in parallel on the worker nodes. Developers should write their program in such a manner that the data is partitioned well to minimise data shuffles and increase the parallelism. Developers can use the custom partitioning feature for effective partitioning of RDDs.
6. Transformations and Actions
RDD supports various types of transformations and actions, which is used by developers to develop a wide variety of data processing applications for Apache Spark cluster. Developers can develop scalable, flexible and powerful data processing applications for the clients.
Transformations and Actions
Now we are going to understand various transformations and actions provided by RDD in Apache Spark. The transformations and actions are a type of operations on the RDD that performs data processing activities in parallel on the worker nodes. Transformations and actions are used in Apache Spark for the logical flow of application, which returns the result of computations. Let's discuss Transformation and Actions in detail:
Transformation
0Transformations on RDD creates new RDD from the existing RDDs. Here are examples of transformation operations:
- map(func): The map transformation operation is applied to each element.
- filter(func): This transformation filters the elements based on a given condition.
- flatMap(func): This transformation is used to flatten the results.
- groupByKey(): It's simply the group transformation where elements are grouped by keys.
- reduceByKey(func): This transformation is used combine values of the same key using a specified function.
Types of Transformations
There are two types of transformations: Narrow Transformation and Wider Transformation. Lets see these transformation in little detail:
Narrow Transformation: In case of narrow transformations operation each input partition contributes to one output partition. In the narrow transformation data is not transferred among the partitions for calculation. In this case data is not shuffled across the custer which makes these operations much faster and efficient. Examples of narrow transformations are map(func), filter(func), flatMap(func), mapPartitions(func), union(otherRDD) and distinct()
1Wider Transformation: Wide operation involves the data from multiple partitions which results in heavy data shuffle between the nodes. Examples of wide transformations are groupByKey() and reduceByKey() functions. Sometime wide transformation may degrade the efficiency of Spark application. So, you should apply these transformations wisely. Functions join(), cogroup() and distinct() are also examples of wide transformation.
Actions
In Apache Spark actions are used to trigger transformations and return the results. These are examples of actions:
- count(): The count action is used to return the number of elements.
- collect(): The collect() action is used to retrieve all the elements to the driver node.
- take(n): This is used to fetch the first n elements.
- saveAsTextFile(path): This action is used to write the RDD data to an external file.
RDD Examples
Now we are going to teach you how to create and use RDDs in PySpark. First of all you should have an Apache Spark Development Environment where you can run the code examples explained here. If you don't know or don't have Apache Spark Development environment then check our tutorial: How to setup Apache Spark Development Environment?
2Step 1: Creating SparkSession
Before running any PySpark code you have to create a SparkSession object. The SparkSession is the entry point for starting running the code on the Apache Spark cluster. It provides the API's for interacting with the Spark Cluster using the programming language. So, we will first create the object of SparkSession and then start using this object to program using RDD. Here is the code for creating SparkSession:
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[1]") \
.appName('roseindia.net') \
.getOrCreate()
We have to import the SparkSession and then use the builder to get or create the SparkSession object.
3Step 2: Creating RDD
Now we will create RDD from the Python list using following code:
# Create RDD from parallelize
data = ["Robot", "Mobile Phones", "Gaming PC", "Gaming PC", "Laptop",
"Office Laptops", "Gaming Laptops", "GPU", "GPU",
"Car", "Programming Books", "Pen", "Pencil"]
rdd = spark.sparkContext.parallelize(data)
In the above code we have created a list called data in Python and used the spark.sparkContext.parallelize(data) method to create RDD from the Python list.
4Step 3: Printing the Content of RDD using collect() action
Now we will use the collect() action on the RDD to get the RDD data on the driver node and then use the Python print() function to print the content of RDD. Here is the complete code of RDD collect() action and use of print() to print the data:
dataCollected = rdd.collect()
print(dataCollected)
# Output
# ['Robot', 'Mobile Phones', 'Gaming PC', ......'Pen', 'Pencil']
Step 4: Create PySpark map() transformation example code
5Now we are going to use the map() transformation and apply the lambda function. Our lambda function takes one element and returns a tuple(x,len(x)). We will get a new RDD with the string data and its length. Here is the complete example of map() transformation on RDD:
rdd2 = rdd.map(lambda x: (x, len(x)))
for element in rdd2.collect():
print(element)
In the above code we are collecting the rdd2 with the help of collect() action and then printing the elements. Here is the output of above code:
('Robot', 5)
('Mobile Phones', 13)
('Gaming PC', 9)
('Gaming PC', 9)
('Laptop', 6)
('Office Laptops', 14)
('Gaming Laptops', 14)
('GPU', 3)
('GPU', 3)
('Car', 3)
('Programming Books', 17)
('Pen', 3)
('Pencil', 6)
Output of above map() transformation:
6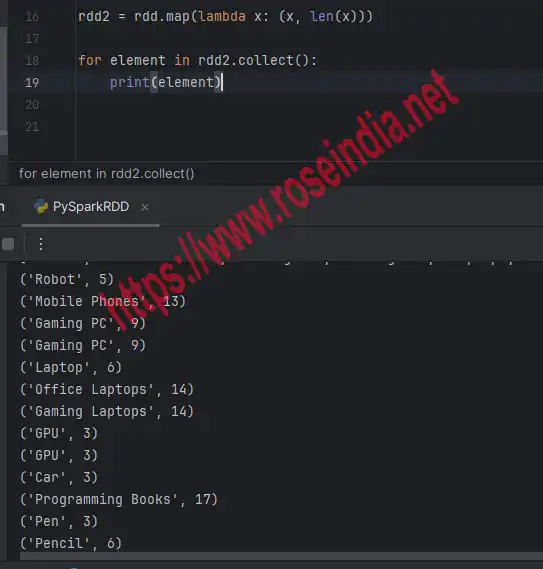
Step 5: RDD filter(func) transformation example
We have used the filter(func) transformation to filter the data with the string "GPU" in the following code:
7
filtered_rdd = rdd.filter(lambda x: x == "GPU")
print("Count:", filtered_rdd.count())
for element in filtered_rdd.collect():
print(element)
# Output
# Count: 2
# GPU
# GPU
Above code also shows the use of count() action on the RDD. The count() action returns 2 as we have only two records returned by applying filter() transformation.
Step 6: Creating example of flatMap(func) transformation in PySpark
As explained about the flatMap(func) returns one or more rows as an output of this operation. He is simple example code that split string with the space and returns multiple rows:
8
sentences = [
"Learning Apache Spark",
"How to use PySpark flatMap tranformation",
"PySpark for beginners",
"What is RDD?"
]
sentencesRdd = spark.sparkContext.parallelize(sentences)
print("Total sentences: ", sentencesRdd.count())
words_rdd = sentencesRdd.flatMap(lambda x: x.split(" "))
print("Total words: ", words_rdd.count())
# Collect the result and print
print(words_rdd.collect())
# Output
# Total sentences: 4
# Total words: 15
# ['Learning', 'Apache', 'Spark', 'How', 'to', 'use', 'PySpark', 'flatMap',
# 'tranformation', 'PySpark', 'for', 'beginners', 'What', 'is', 'RDD?']
Above code shows you how to use the flapMap() transformation in PySpark. Here is the screenshot of the code:
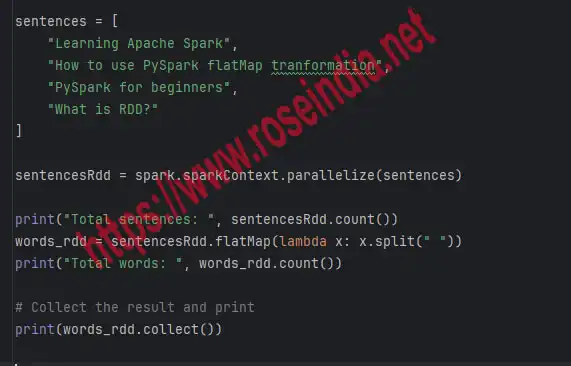
Step 7: Example of groupByKey() example
9Here is simple example of groupByKey()
rdd_group = rdd2.groupByKey()
for element in rdd_group.collect():
print(element)
Step 8: Example of reduceByKey(func) transformation
Here is simple example of reduceByKey(func) transformation in PySpark:
0
reduceByKey = rdd2.reduceByKey(lambda a,b: a+b).collect()
print(reduceByKey)
Step 9: Create example of take(n) action
Here is an example of take(n) action that retrieves 2 rows from the RDD:
nRdd = rdd2.take(2)
print(nRdd)
Step 10: Write example code of saveAsTextFile(path) action
1Here is example code of saveAsTextFile(path) action:
rdd.saveAsTextFile("data.txt")
Above code saves the rdd into a text file.
Full source code:
2
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[1]") \
.appName('roseindia.net') \
.getOrCreate()
# Create RDD from parallelize
data = ["Robot", "Mobile Phones", "Gaming PC", "Gaming PC", "Laptop",
"Office Laptops", "Gaming Laptops", "GPU", "GPU",
"Car", "Programming Books", "Pen", "Pencil"]
rdd = spark.sparkContext.parallelize(data)
dataCollected = rdd.collect()
print(dataCollected)
rdd2 = rdd.map(lambda x: (x, len(x)))
for element in rdd2.collect():
print(element)
filtered_rdd = rdd.filter(lambda x: x == "GPU")
print("Count:", filtered_rdd.count())
for element in filtered_rdd.collect():
print(element)
sentences = [
"Learning Apache Spark",
"How to use PySpark flatMap tranformation",
"PySpark for beginners",
"What is RDD?"
]
sentencesRdd = spark.sparkContext.parallelize(sentences)
print("Total sentences: ", sentencesRdd.count())
words_rdd = sentencesRdd.flatMap(lambda x: x.split(" "))
print("Total words: ", words_rdd.count())
# Collect the result and print
print(words_rdd.collect())
rdd_group = rdd2.groupByKey()
for element in rdd_group.collect():
print(element)
reduceByKey = rdd2.reduceByKey(lambda a,b: a+b).collect()
print(reduceByKey)
nRdd = rdd2.take(2)
print(nRdd)
rdd.saveAsTextFile("data.txt")
You can run these code in PySpark terminal to understand it and master RDD for your project.
Advantages of RDD
Now we are going to explore the advantages of using RDD in Apache Spark.
Advantages of RDD
Now we will explore the various advantages of using RDD for data processing in Apache Spark application.
31. Fault Tolerance Without Overhead
Apache Spark uses lineage graphs for the generation of RDD which makes a perfect solution to regenerate the lost RDD partitions. Further RDDs are immutable which means it cannot be modified and only generated with the transformations on existing RDD. This makes RDDs lightweight and efficient for processing large amounts of data at scale.
2. Scalability
RDDs can be partitioned on multiple partitions which can be distributed over multiple worker nodes. It can handle terabytes to petabytes of data distributed over cluster nodes. So, RDDs can be scaled to handle terabytes to petabytes of data.
3. Flexibility
RDDs support multiple types of data including CSV, JSON, raw and others which means it can be used to process diverse data types. In Apache Spark we can access data from HDFS, S3, or databases, which makes it very flexible for programmers.
44. Machine Learning
RDDs can be used in the data, preparation, model training and inferencing tasks. Apache Spark ML supports many different types of machine learning models and you be able to develop, train and infer your models on the Apache Spark.
5. Fine-Grained Control
Apache Spark provides fine-grained control of RDD where you will have full control over data distribution, transformations and other types of data operations. This makes it easy for the programmers to use RDD for complex data processing tasks.
6. Ease of Debugging
The immutability and data lineage graph makes it simple for the developers to debug their code efficiently. You will be able to debug your intermediate RDDs in a much simpler way. You can also use a jupyter notebook for development of your Apache Spark code which makes programming a fun.
57. Partitioning
RDDs are partitioned into small chunks called partitions, which are loaded in the memory of worker nodes in the clutter. The number of partitions is a key factor in parallel processing of data. Spark process the data of data partitions in parallel on the work nodes in the cluster.
When to Use RDDs?
RDDs are mostly used in machine learning and the process of raw data. RDDs can be used to process unstructured or semi-structured data, such as:
- Log files
- Sensor data
- Binary data
RDDs are schema less which makes it more flexible for handling raw data formats. It is also used for low-level transformation where there is a need for complex custom transformation.
6Use Cases of RDD
Real life use cases of RDS includes Data Preprocessing and Cleaning, Machine Learning at Scale, Real-Time Stream Processing, Graph Processing, Log Analysis and ETL pipelines.
Performance Tips for RDDs
RDDs provide more control on the setting, partitioning and use of various techniques for optimising the performance. Here are the things you can do to increase the performance of your RDD base Apache Spark applications:
- Use Kryo Serialization: You can use the Kryo serialization for faster data processing and reduced memory overhead while processing large amounts of data. Kryo Serialization is a fast and efficient serialization framework for Java. This framework is designed to handle complex object graphs with the efficiency and rapid input/output operations.
- Optimize Partitions:
As a developer you should use repartition or coalesce wisely to balance workload distribution across nodes.
- Cache or Persist RDDs: You can use the various caching techniques which will help in increasing the overall performance. You can cache intermediate results to speed up iterative operations. It's better to choose appropriate storage levels (e.g., MEMORY_AND_DISK) to enhance performance. But various settings may depend on a particular use case. You have to experiment with various settings to see which is giving better performance for your job.
- Minimize Shuffles: Minimizing the data shuffles will definitely increase the performance of your Apache Spark Job. You should design transformations to avoid shuffles, which are expensive due to network IO.
- Broadcast Variables: You should use broadcast variables to reduce the overhead of repeatedly sending large datasets to worker nodes. In most of the use cases broadcasting of data provides much better performance.
Limitations of RDD
RDDs are powerful data structures in Apache Spark which can be used for many use cases, but there are few limitations of RDDs. Here are the list of few limitations of RDDs in Apache Spark:
7- No Schema
- More Code for common tasks
- No Query optimization and others
Conclusion
In this section we have explored RDDs in much detail. The Resilient Distributed Dataset or RDD for short is fundamental data structure in Apache Spark which is used for low level data processing activities. RDDs are used in machine learning, log file processing, and processing of structured and unstructured data.
Check the advanced data structures like Dataframe, Datasets at Apache Spark data structures tutorial page.
Related Questions
What is the difference between RDD, Dataset and DataFrame in Spark?
RDD is used to process raw data and when we need fine grained control over the data processing. DataFrame is used when we have to process structured data using SQL-like queries. Dataset is used when we have to process strongly-typed data and with structured operations.
8What are the advantages of keeping Apache Spark RDD immutable?
In Apache Spark RDDs are designed to be immutable and this is done to enhance performance, data protection, data re-generation of lost data and maintain consistency in its distributed environment. Once RDDs are created it can be modified and a new RDD is created by performing transformation on the existing RDD.
What is RDD in Spark with an example?
Check above examples, we have provided you many examples of creating and using RDD in PySpark code.
What is the difference between dataframe and RDD?
RDDs are used for processing raw data while data frames are used for processing structured data such as relational tables. Dataframe uses SQL query for processing the data over a distributed cluster.
9What are the limitations of RDD in Spark?
The limitations of RDD's include Lack of Query Optimization, No Schema Support, Performance Overheads, Verbosity and Complexity, Limited Language Support, Inefficient for Aggregations and Joins, Inefficiency with Small File Processing and Lack of Advanced Optimizations. So, you should use RDD's with proper care and analyze the better option for your use case.
What is an RDD Lineage?
In Apache Spark Lineage graph is used to plan and execute the jobs on the distributed cluster in fault tolerant manner. The RDD Lineage is also known as RDD Graph or RDD Dependency, refers to the sequence of execution of the Spark job to achieve a particular result.
Example of Lineage graph:
0rdd1 -> rdd2 (filter) -> rdd3 (map) -> rdd4 (reduceByKey).
Why use RDD?
RDD is used to process no-structured and raw data in Apache Spark. RDDs are used when there is a need for processing raw data with greater control.